RabbitMQ 파이썬 튜토리얼 06 - RPC
21 Sep 2018
튜토리얼 리스트
전제조건
이 튜토리얼에서는 RabbitMQ가 표준 포트(5672)의 localhost에 설치되어 실행되고 있다고 가정합니다. 다른 호스트, 포트 또는 자격 증명을 사용하는 경우 연결 설정을 변경해야 합니다.
이 포스트에서는
두 번째 포스트에서는 작업 큐를 사용하여 시간이 많이 소요되는 작업을 여러 작업자에게 배포하는 방법을 배웠습니다.
그러나 원격 컴퓨터에서 함수를 실행하고 결과를 기다릴 필요가 있다면 어떻게 해야 할까요? 그건 다른 이야기입니다. 이 패턴은 일반적으로 원격 프로 시저 호출 또는 RPC로 알려져 있습니다.
이 포스트에서는 RabbitMQ를 사용하여 클라이언트와 확장 가능한 RPC 서버인 RPC 시스템을 구축 할 것입니다. 예제에서 피보나치 숫자를 반환하는 더미 RPC 서비스를 만들 것입니다.
클라이언트 인터페이스
RPC 서비스를 사용하는 방법을 설명하기 위해 간단한 클라이언트 클래스를 만들 것입니다. RPC 요청을 보내고 응답이 수신될 때까지 기다리는 call 이라는 메서드를 호출합니다.
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print("fib(4) is %r" % result)
RPC 주의점
RPC는 컴퓨팅에서 꽤 일반적인 패턴이지만, 종종 비판을 받습니다. 프로그래머가 함수 호출이 로컬인지 또는 느린 RPC인지 여부를 알지 못하는 경우 문제가 발생합니다. 그런 혼란은 예기치 않은 시스템을 초래하고 디버깅에 불필요한 복잡성을 추가합니다. 소프트웨어를 단순화하는 대신 RPC를 잘못 사용하면 유지 보수가 불가능한 스파게티 코드가 생길 수 있습니다.
이를 염두에두고 다음 조언을 고려하십시오.:
- 어떤 함수 호출이 로컬이고 어떤 것이 원격인지 분명해야 합니다.
- 시스템을 문서화하십시오. 구성 요소 간의 종속성을 명확하게 만듭니다.
- 오류 케이스를 처리하십시오. RPC 서버가 오랫동안 작동하지 않을 때 대응은?
어떻게 구현할지 의심스러운 경우 RPC를 피하십시오. 가능한 경우 RPC와 같은 차단 대신 비동기 파이프 라인을 사용해야 합니다. 결과는 비동기적으로 다음 계산 단계로 푸시 됩니다.
Callback Queue
RPC는 RabbitMQ에서 구현하기 쉽습니다. 클라이언트가 요청 메시지를 보내고 서버가 응답 메시지로 응답합니다. 응답을 받으려면 클라이언트가 요청과 함께 ‘callback’ 큐 주소를 보내야합니다.
result = channel.queue_declare(exclusive=True)
callback_queue = result.method.queue
channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = callback_queue,
),
body=request)
# ... and some code to read a response message from the callback_queue ...
메시지 퍼라퍼티
AMQP 0-9-1 프로토콜은 메시지와 함께 제공되는 14개의 속성 집합을 미리 정의합니다. 다음을 제외하고 대부분의 속성은 거의 사용되지 않습니다.
- delivery_mode : 메시지를 지속적(값2) 또는 일시 (다른 값)으로 표시합니다. 두 번째 포스트에서 이 속성을 기억할 수 있습니다.
- content_type : 인코딩의 MIME 유형을 설명하는 데 사용됩니다. 예를 들어 자주 사용되는 JSON 인코딩의 경우이 속성을 ‘application/json’으로 설정하는 것이 좋습니다.
- reply_to : 일반적으로 콜백 큐의 이름을 지정하는 데 사용됩니다.
- correlation_id : RPC 응답을 요청과 상관시키는 데 유용합니다.
Correlation id
위에 제시된 방법에서는 서비스에서 사용하는 모든 RPC 요청에 대한 콜백 큐를 생성해야 합니다. 그렇게 하려면 꽤 비효율적이 됩니다. 다행스럽게도 쉬운 방법이 있습니다. 클라이언트 당 하나의 콜백 큐을 생성합시다. 새로운 큐가 생겨 응답이 어떤 요청에 속하는지 명확하지 않습니다. 그것은 correlation_id 속성이 사용된 때입니다. 모든 요청에 대해 고유 한 값으로 설정합니다. 나중에 콜백 큐에서 메시지를 받으면이 속성을 살펴보고 이를 기반으로 응답과 요청을 일치시킬 수 있습니다. 알 수 없는 correlation_id 값이 표시되면 메시지를 안전하게 삭제할 수 있습니다.
오류가 발생하지 않고 콜백 큐에서 알 수 없는 메시지를 무시해야 하는 이유는 무엇일까요? 서버 측에서 경쟁 조건이 발생할 가능성이 있기 때문입니다. 가능성은 낮지만 RPC 서버가 응답을 보낸 직후에 요청에 대한 확인 메시지를 보내기 전에 죽을 수도 있습니다. 이 경우 다시 시작된 RPC 서버가 요청을 다시 처리합니다. 그래서 클라이언트에서 우리는 중복된 응답을 정상적으로 처리해야 하며 RPC는 이상적으로 멱등수가 되어야 합니다.
정리
우리의 RPC는 다음과 같이 작동합니다 :
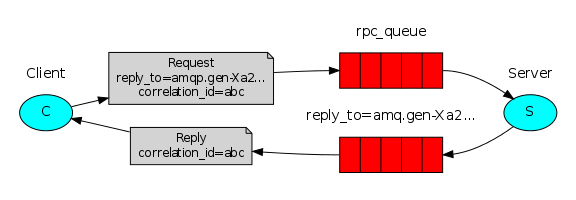
클라이언트가 시작되면 익명의 전용 콜백 큐가 생성됩니다. RPC 요청의 경우 클라이언트는 콜백 큐에 설정된 reply_to와 모든 요청에 대해 고유 한 값으로 설정된 correlation_id의 두 가지 속성을 가진 메시지를 보냅니다. 요청은 rpc_queue 큐로 보내집니다. RPC 작업자 (일명 : 서버)는 해당 큐에 대한 요청을 기다리고 있습니다. 요청이 나타나면 작업을 수행하고 reply_to 필드의 큐을 사용하여 결과가 포함 된 메시지를 클라이언트에 보냅니다. 클라이언트는 콜백 큐에있는 데이터를 기다립니다. 메시지가 나타나면 correlation_id 등록 정보를 확인합니다. 요청의 값과 일치하면 응용 프로그램에 응답을 반환합니다.
최종 코드
rpc_server.py:
#!/usr/bin/env python
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties = pika.BasicProperties(correlation_id = props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()
서버 코드는 다소 간단합니다.
- (4) 늘 그렇듯이 우리는 연결을 설정하고 큐을 선언하는 것으로 시작합니다.
- (11) 피보나치 함수를 선언합니다. 유효한 양의 정수만 입력한다고 가정합니다.
- (19) RPC 서버의 핵심 인 basic_consume에 대한 콜백을 선언합니다. 요청을 받으면 실행됩니다. 그것은 작업을 수행하고 응답을 되돌려 보냅니다.
- (32) 우리는 하나 이상의 서버 프로세스를 실행할 수 있습니다. 여러 서버에 균등하게 부하를 분산하려면 prefetch_count 설정을 지정해야합니다.
rpc_client.py:
#!/usr/bin/env python
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
클라이언트 코드는 약간 더 복잡합니다.
- (7) 우리는 연결, 채널을 설정하고 응답을 위한 독점 ‘callback’ 큐을 선언합니다.
- (16) 우리는 RPC 응답을 받을 수 있도록 ‘callback’ 큐에 가입합니다.
- (18) 모든 응답에서 실행되는 ‘on_response’ callback은 correlation_id가 찾고 있는 모든 응답 메시지에 대해 매우 간단한 작업을 수행합니다. 그렇다면 self.response에 응답을 저장하고 comsuming 루프를 중단합니다.
- (23) 다음으로, 우리는 main call method를 정의합니다. 실제 RPC 요청을합니다.
- (24)이 방법에서는 먼저 고유 한 correlation_id 번호를 생성하고 저장합니다. ‘on_response’ callback 함수는 이 값을 사용하여 적절한 응답을 확인 합니다.
- (25) 그런 다음 reply_to 및 correlation_id의 두 가지 등록 정보를 사용하여 요청 메시지를 게시합니다.
- (32)이 시점에서 우리는 앉아서 적절한 응답이 도착할 때까지 기다릴 수 있습니다.
- (33) 그리고 마침내 응답을 사용자에게 돌려 보냅니다.
RPC 서비스가 준비되었습니다. 서버를 시작할 수 있습니다.
python rpc_server.py
# => [x] Awaiting RPC requests
피보나치 수를 요청하려면 클라이언트를 실행하십시오.
python rpc_client.py
# => [x] Requesting fib(30)
RPC 서버가 너무 느리면 다른 RPC 서버를 실행하여 확장 할 수 있습니다. 새 콘솔에서 두 번째 rpc_server.py를 실행 해보십시오. 클라이언트 측에서는 RPC가 하나의 메시지만 보내고 받아야합니다. queue_declare 와 같은 동기 호출은 필요하지 않습니다. 결과적으로 RPC 클라이언트는 단일 RPC 요청에 대해 하나의 네트워크 왕복만 필요합니다.
우리 코드는 여전히 매우 단순하며 더 복잡한 그러나 중요한 문제를 해결하려고 하지 않습니다.
- 실행중인 서버가없는 경우 클라이언트가 어떻게 대응해야합니까?
- 클라이언트가 RPC에 대해 일정 시간 제한이 있어야합니까?
- 서버가 오작동하고 예외가 발생하면 클라이언트에게 전달해야합니까?
- 처리하기 전에 잘못된 수신 메시지 (예 : 경계 검사)를 방지합니다.
실제 사용 가능한 서비스는 위와 같은 문제를 해결해야 합니다.