RabbitMQ 파이썬 튜토리얼 02 - Work Queue
21 Sep 2018
튜토리얼 리스트
전제조건
이 튜토리얼에서는 RabbitMQ가 표준 포트 (5672)의 localhost에 설치되어 실행되고 있다고 가정합니다. 다른 호스트, 포트 또는 자격 증명을 사용하는 경우 연결 설정을 조정해야 합니다
우리는 Pika RabbitMQ client version 0.11.0 을 사용합니다.
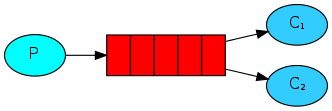
이 포스트에서는
첫 번째 포스트에서는 이름을 지정한 큐에서 메시지를 주고 받는 프로그램을 작성했습니다. 이번 포스트에서는 여러 작업자에게 시간이 많이 드는 작업을 배포하는 데 사용할 작업 큐을 만듭니다.
작업 큐의 주된 아이디어는 자원 집약적인 작업을 즉시 수행하지 않고 완료 될 때까지 기다리지 않아야 한다는 것입니다. 대신에 나중에 수행 할 작업을 예약합니다. 우리는 작업을 메시지로 캡슐화하여 큐로 보냅니다. 백그라운드에서 실행 중인 작업자 프로세스는 작업을 팝업하고 결국 작업을 실행합니다. 많은 작업자를 실행하면 작업이 그들 사이에 공유됩니다.
이 개념은 짧은 HTTP 요청 창에서 복잡한 작업을 처리하는 것이 불가능한 웹 응용 프로그램에서 특히 유용합니다.
이전 포스트에서 “Hello World!”라는 메시지를 보냈습니다. 이제 복잡한 작업을 나타내는 문자열을 보냅니다. 리사이즈 할 이미지 나 렌더링할 pdf 파일 같은 실제 작업이 없으므로 time.sleep() 함수를 사용하여 바쁜 것처럼 하여 가짜로 만들어 보겠습니다. 문자열의 점의 개수를 복잡도로 사용합니다. 모든 점은 1 초의 “일”을 나타낼 것입니다. 예를 들어, Hello …로 표시된 가짜 작업은 3 초가 걸립니다.
앞의 예제에서 send.py 코드를 약간 수정하여 명령 줄에서 임의의 메시지를 보낼 수 있습니다. 이 프로그램은 작업 큐에 작업을 예약하므로 new_task.py 라는 이름을 지정합니다.
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print(" [x] Sent %r" % message)
우리의 오래된 receive.py 스크립트는 또한 약간의 변경이 필요합니다. 메시지 본문의 모든 점에 대해 1초의 가상의 일을 해야 합니다. 그것은 큐에서 메시지를 팝업하고 작업을 수행하므로 worker.py라고 합시다.
import time
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
라운드-로빈 배분 (Round-robin dispatching)
작업 큐을 사용하면 작업을 쉽게 병렬 처리 할 수 있다는 것은 작업 큐의 장점 중 하나입니다. 우리가 백로그(작업)를 축적하고 있다면, 우리는 더 많은 클라이언트 작업자를 추가 하는 방식으로 쉽게 확장 할 수 있습니다.
먼저 두 개의 worker.py 스크립트를 동시에 실행 해 봅시다. 3 개의 콘솔이 열려 있어야 합니다. 2 명이 worker.py 스크립트를 실행합니다. 이 콘솔은 우리의 두 컨슈머 C1과 C2가 될 것입니다.
둘 다 큐에서 메시지를 가져 오지만 어떻게 될까요?
# shell 1
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
# shell 2
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
세 번째 터미널에서 새로운 작업을 보낼 것입니다. 컨슈머를 시작하면 메시지를 보낼 수 있습니다.
# shell 3
python new_task.py First message.
python new_task.py Second message..
python new_task.py Third message...
python new_task.py Fourth message....
python new_task.py Fifth message.....
우리 컨슈머들이 처리한 것을 봅시다 :
# shell 1
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received 'First message.'
# => [x] Received 'Third message...'
# => [x] Received 'Fifth message.....'
# shell 2
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received 'Second message..'
# => [x] Received 'Fourth message....'
기본적으로 RabbitMQ는 각 메시지를 순서대로 다음 작업 클라이언트에게 보냅니다. 평균적으로 모든 작업 클라이언트는 동일한 수의 메시지를 받게 됩니다. 이 메시지 배포 방법을 라운드 로빈이라고 합니다. 3 명 이상의 작업 클라이언트를 실행해 보세요.
메시지 처리 승인(Message acknowledgment)
작업을 수행하는 데 몇 초가 걸릴 수 있습니다. 작업 클라이언트 중 한 명이 긴 작업을 시작하고 부분적으로 만 수행되어 사망하는 경우 어떻게 되는지 궁금 할 수 있습니다. RabbitMQ가 작업 클라이언트 프로그램에게 메시지를 전달하면 현재 코드로 삭제 즉시 표시됩니다. 이 경우, 작업 클라이언트를 죽이면 처리 중인 메시지가 손실됩니다. 이 특정 작업 클라이언트에게 발송되었지만 아직 처리되지 않은 모든 메시지도 손실됩니다. 그러나 우리는 어떤 일도 잃고 싶지 않습니다. 작업 클라이언트가 사망하면 작업을 다른 작업 클라이언트에게 전달하고 싶습니다.
메시지가 손실되지 않도록 RabbitMQ는 메시지 확인을 지원합니다. ack (nowledgement)는 특정 메시지가 수신되고 처리되었으며 RabbitMQ가 메시지를 삭제할 수 있다고 RabbitMQ에게 알리기 위해 작업 클라이언트가 보낸 답입니다.
ack를 전송하지 않고 작업 클라이언트가 죽거나 (채널이 닫히거나 연결이 끊어 지거나 TCP 연결이 끊어지는 경우) RabbitMQ는 메시지가 완전히 처리되지 않았음을 인식하고 큐에 다시 대기합니다. 동시에 다른 작업 클라이언트가 온라인 상태이면 다른 작업 클라이언트에게 신속하게 다시 전달합니다. 그렇게 하면 근로자가 가끔씩 사망하더라도 메시지를 잃어 버리지 않을 것입니다.
메시지 시간 초과가 없습니다. RabbitMQ는 작업 클라이언트가 사망 할 때 메시지를 재전송합니다. 메시지 처리가 매우 오랜 시간이 걸리는 경우에도 괜찮습니다. 수동 메시지 확인은 기본적으로 설정되어 있습니다. 앞의 예제에서 우리는 no_ack = True 플래그를 통해 명시 적으로 해제 시켰습니다. 작업을 마친 후에는이 플래그를 제거하고 작업 클라이언트에게 적절한 확인을 보내야합니다.
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
이 코드를 사용하면 메시지를 처리하는 동안 CTRL + C를 사용하여 작업 클라이언트를 죽이더라도 아무 것도 손실되지 않습니다. 작업 클라이언트가 죽은 직후 모든 미확인 메시지가 재전송됩니다. 수신 확인은 수신 된 것과 동일한 채널을 통해 전송되어야 합니다. 다른 채널을 사용하여 확인 응답을 시도하면 채널 수준 프로토콜 예외가 발생합니다.
미처리된 처리 승인(Forgotten acknowledgment)
basic_ack을 놓치는 것은 흔한 실수입니다. 쉬운 오류이지만 그 결과는 심각합니다. 클라이언트가 종료되면 메시지가 다시 배달되지만 (임의 재 배달과 같이 보일 수 있음) RackbitMQ는 포장되지 않은 메시지를 릴리스 할 수 없으므로 점점 더 많은 메모리를 사용합니다. 이런 종류의 실수를 디버깅하려면 rabbitmqctl을 사용하여 messages_unacknowledged 필드를 인쇄하십시오.
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged윈도우에서는
sudo를 빼고 사용합니다:rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
메시지 유지성(Message durability)
우리는 소비자가 사망하더라도 작업이 손실되지 않도록 하는 방법을 배웠습니다. 그러나 RabbitMQ 서버가 중지되면 우리의 작업은 여전히 손실됩니다.
RabbitMQ가 종료되거나 충돌하면 사용자가 알리지 않는 한 큐과 메시지를 잊어 버리게됩니다. 메시지가 손실되지 않도록 하려면 큐와 메시지를 모두 durable 표시해야합니다.
첫째, 우리는 RabbitMQ가 결코 우리 큐를 잃지 않도록 해야합니다. 그렇게하기 위해서 우리는 그것을 durable 으로 선언 할 필요가 있습니다.
channel.queue_declare(queue='hello', durable=True)
이 명령은 그 자체로 정확하지만, 우리의 설정에서는 작동하지 않습니다. 그것은 hello 라는 큐를 이미 정의했기 때문입니다. 이 큐는 durable이 아닙니다. RabbitMQ는 다른 매개 변수로 기존 큐을 재정의하는 것을 허용하지 않으며 이를 수행하려는 프로그램에 오류를 반환합니다. 하지만 빠른 해결 방법이 있습니다. 예를 들어 ‘task_queue’와 같이 다른 이름을 가진 큐을 선언합시다.
channel.queue_declare(queue='task_queue', durable=True)
이 queue_declare 변경은 생산자 코드와 소비자 코드 모두에 적용 되어야 합니다. 이 시점에서 우리는 RabbitMQ가 다시 시작 되더라도 ‘task_queue’ 큐이 손실되지 않는다고 확신합니다. 이제 delivery_mode 속성에 값 2를 제공하여 메시지를 영구적으로 표시해야합니다.
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
메시지 영구성(message persistence)
메시지를 영구적으로 표시한다고 해서 메시지가 손실되지 않는다고 보장 할 수는 없습니다. RabbitMQ가 메시지를 디스크에 저장하도록 알려주지만, RabbitMQ가 메시지를 수락하고 아직 저장하지 않은 경우에도 짧은 시간 창이 있습니다. 또한, RabbitMQ는 모든 메시지에 대해 fsync(2)를 수행하지 않습니다. 캐시에 저장 될뿐 실제로 디스크에 기록되지는 않습니다. 지속성 보장은 강하지는 않지만 단순
작업 큐만큼 충분합니다.보다 강력한 보증이 필요한 경우 게시자 확인을 사용할 수 있습니다
Fair dispatch
당신은 파견이 우리가 원하는만 큼 정확하게 작동하지 않는다는 것을 알았을 것입니다. 예를 들어 두 명의 근로자가 있는 상황에서 모든 홀수 메시지가 무거우며 메시지 조차 가벼울 지라도 한 작업 클라이언트는 계속 바빠지며 다른 작업 클라이언트는 업무를 거의하지 않을 것입니다. 음, RabbitMQ는 그것에 대해 아무것도 모르고 있으며 메시지를 고르게 발송합니다. 이것은 RabbitMQ가 메시지가 큐에 들어갈 때 메시지를 전달하기 때문에 발생합니다. 그것은 소비자에 대한 승인되지 않은 메시지의 수를 조사하지 않습니다. 그것은 단지 맹목적으로 n 번째 메시지를 n 번째 소비자에게 파견합니다.
이를 막기 위해 basic.qos 메소드를 prefetch_count = 1 설정과 함께 사용할 수 있습니다. 이것은 RabbitMQ에게 한 번에 하나 이상의 메시지를 제공하지 말 것을 지시합니다. 즉, 이전 메시지를 처리하고 확인하기 전까지는 새 메시지를 작업자에게 보내지 마십시오. 대신, 아직 바쁘지 않은 다음 작업자에게 작업을 보냅니다.
channel.basic_qos(prefetch_count=1)
Note about queue size
모든 작업 클라이언트가 바쁘면 큐이 가득 찰 수 있습니다. 당신은 그것에 주시하고, 더 많은 근로자를 추가하거나 메시지 TTL을 사용하고 싶을 것입니다.
최종 코드
new_task.py 스크립트의 최종 코드 :
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
worker.py 최종 코드:
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
메시지 확인 및 prefetch_count를 사용하여 작업 큐을 설정할 수 있습니다. 내구성 옵션(durable)을 사용하면 RabbitMQ를 다시 시작한 후에도 작업을 유지할 수 있습니다.